Материалы по тегу: intel xe
|
12.04.2023 [16:24], Сергей Карасёв
Внезапный пересмотр модельного ряда ускорителей Intel Max объясним желанием не потерять рынок КитаяКорпорация Intel, по сообщению ресурса Tom's Hardware, отменила выпуск ускорителей Data Center GPU Max 1350 (Ponte Vecchio), предназначенных для использования в НРС-системах и оборудовании для ЦОД. Данное решение, как сообщается, связано с реструктуризацией на фоне ухудшившегося финансового положения и снижения продаж. Однако истинная причина может оказаться гораздо прозаичнее. Как отмечается на сайте самой Intel, решения Data Center GPU Max 1350 были официально анонсированы в I квартале 2023 года. Планировалось, что они будут производиться до января 2026-го. Конфигурация включает 112 ядер Xe, 112 блоков трассировки лучей и 96 Гбайт памяти HBM2e. Показатель TDP был заявлен на отметке 450 Вт. Intel также предложит более мощный ускоритель Data Center GPU Max 1550 с опцией воздушного охлаждения, хотя изначально он планировался только для систем с СЖО. 
Источник: Intel А вот вместо Data Center GPU Max 1350 Intel готовит решение Data Center GPU Max 1450, выход которого на рынок запланирован в конце 2023 года. Предположительно, это будет урезанная версия изделия Data Center GPU Max 1550, которая получит 128 ядер Xe, 128 Гбайт HBM2e, TDP на уровне 450 Вт. Компания прямо говорит о сниженной I/O-производительности. Ранее Intel уже отказалась от ускорителей Rialto Bridge, а выпуск Falcon Shores — перенесла. Как сообщает The Register, отказ Intel от выпуска Data Center GPU Max 1350 может быть связан с желанием корпорации укрепить позиции на «других рынках». И речь, судя по всему, идёт в первую очередь о Китае. Благодаря пониженной по сравнению с Data Center GPU Max 1550 производительности Intel сможет поставлять новинку в КНР. Санкции, объявленные прошлой осенью, запрещают экспорт в Китай изделий со скоростью обмена данными 600 Гбайт/с и выше, и Data Center GPU Max 1450 должен укладываться в допустимые нормы. На Китай приходится значительная часть доходов Intel, а учитывая рост востребованности ИИ-приложений и НРС-услуг, появление Data Center GPU Max 1450 может укрепить положение корпорации на рынке Поднебесной. Ранее NVIDIA, для которой китайский рынок тоже очень важен, уже пошла на аналогичный шаг, сначала представив ускоритель A800 (урезанный вариант A100), а затем и H800 (аналог H100).
06.03.2023 [16:30], Владимир Мироненко
Новые задержки у Intel: выпуск ускорителей Rialto Bridge отменён, а Falcon Shores — отложенКомпания Intel опубликовала в конце прошлой недели письмо вице-президента и главы подразделения Super Compute Group Джеффа Маквея (Jeff McVeigh), в котором, помимо обновлённой информации о состоянии линейки продуктов серверных ускорителей вычислений Intel и их принятии клиентами, было объявлено о ряде кардинальных изменений планов компании по поводу будущих продуктов этой категории. В частности, Intel отказалась от производства ускорителей серии Rialto Bridge, выход которых был намечен на текущий год. Вместо этого компания сразу перейдёт к выпуску чипов Falcon Shores с более новой версией архитектуры Intel Xe. Правда, их выход теперь запланирован на 2025 год вместо 2024-го. Следует также отметить, что если ранее Intel планировала выпуск Falcon Shores в форм-факторе гибридных (XPU) чипов, объединяющих CPU, ускорители и память на основе чиплетов (тайлов в терминологии Intel), то теперь первыми появятся HPC-ускорители следующего поколения без CPU-ядер. Компания пояснила ресурсу ServeTheHome, что по-прежнему придерживается планов по выпуску гибридных (XPU) чипов Falcon Shores, но они увидят свет немного позже. Это означает, что как минимум до 2026 года NVIDIA и AMD будут опережать Intel в деле внедрения архитектур следующего поколения. 
Источник изображения: Intel Как отметил ресурс AnandTech, положительным моментом является то, что Intel не отказывается от архитектуры Xe, которая используется во многих её продуктах, от встроенной графики до HPC-ускорителей, что подчёркивает её важность и жизнеспособность. Отмена Rialto Bridge в сочетании с задержкой Falcon Shores является серьёзной неудачей для Intel, но в итоге она просто заменяет одну итерацию Xe другой, более продвинутой. Изменения планов Intel также коснулись семейства серверных ускорителей Intel Flex для облачных игр и кодирования мультимедиа, поскольку Intel отказалась от запуска Lancaster Sound (также известного как Next Sound) в пользу следующего поколения ускорителей Melville Sound, разработка которых будет ускорена. Intel не назвала точной даты презентации данного решения. Ранее его выход ожидался в те же сроки, что и у Falcon Shores. Согласно Intel, изменения планов относительно Intel Flex позволят ей соответствовать двухлетнему графику выпуска серверных ускорителей. Её конкуренты, NVIDIA и AMD, последние годы работают в таком же режиме. По словам Intel, это изменение «соответствует ожиданиям клиентов в отношении внедрения новых продуктов и даёт время для развития их экосистем».
16.12.2022 [15:26], Сергей Карасёв
В Аргентине появится 15,7-Пфлопс суперкомпьютер на платформе Intel MaxМинистр науки, технологий и инноваций Аргентины Даниэль Фильмус (Daniel Filmus) и министр обороны страны Хорхе Тайана (Jorge Taiana) рассказали о новом комплексе высокопроизводительных вычислений, который планируется ввести в эксплуатацию весной 2023 года. Безымянный пока суперкомпьютер расположится в вычислительном центре Национальной метеорологической службы Аргентины. Созданием системы занимаются специалисты Lenovo. Отличительной особенностью системы станет то, что они будет использовать исключительно процессоры и ускорители Intel Max. Комплекс объединит 5120 ядер процессоров Intel Max (HBM-версии чипов Xeon Sapphire Rapids) суммарной производительностью около 440 Тфлопс. Кроме того, будут задействованы 296 ускорителей Intel Max (Ponte Vecchio) с общим быстродействием 15,3 Пфлопс. Таким образом, пиковая производительность суперкомпьютера в целом составит примерно 15,7 Пфлопс. С таким показателем он мог бы претендовать на 82-е место в нынешнем рейтинге TOP500. Система получит 1,66 Пбайт памяти, 400G-сеть и систему прямого жидкостного охлаждения. Потребляемая мощность составит приблизительно 233 кВт. 
Источник изображения: Intel Суперкомпьютер планируется применять для широкого спектра научных задач, таких как разработка лекарственных препаратов, биоинформатика, наука о данных, искусственный интеллект и моделирование атмосферы. Нужно отметить, что сейчас Национальная метеорологическая служба Аргентины использует HPC-систему Huayra Muyu с пиковым быстродействием 370 Тфлопс.
10.11.2022 [01:55], Игорь Осколков
Intel объединила HBM-версии процессоров Xeon Sapphire Rapids и ускорители Xe HPC Ponte Vecchio под брендом MaxВ преддверии SC22 и за день до официального анонса AMD EPYC Genoa компания Intel поделилась некоторыми подробностями об HBM-версии процессоров Xeon Sapphire Rapids и ускорителях Ponte Vecchio, которые теперь входят в серию Intel Max. 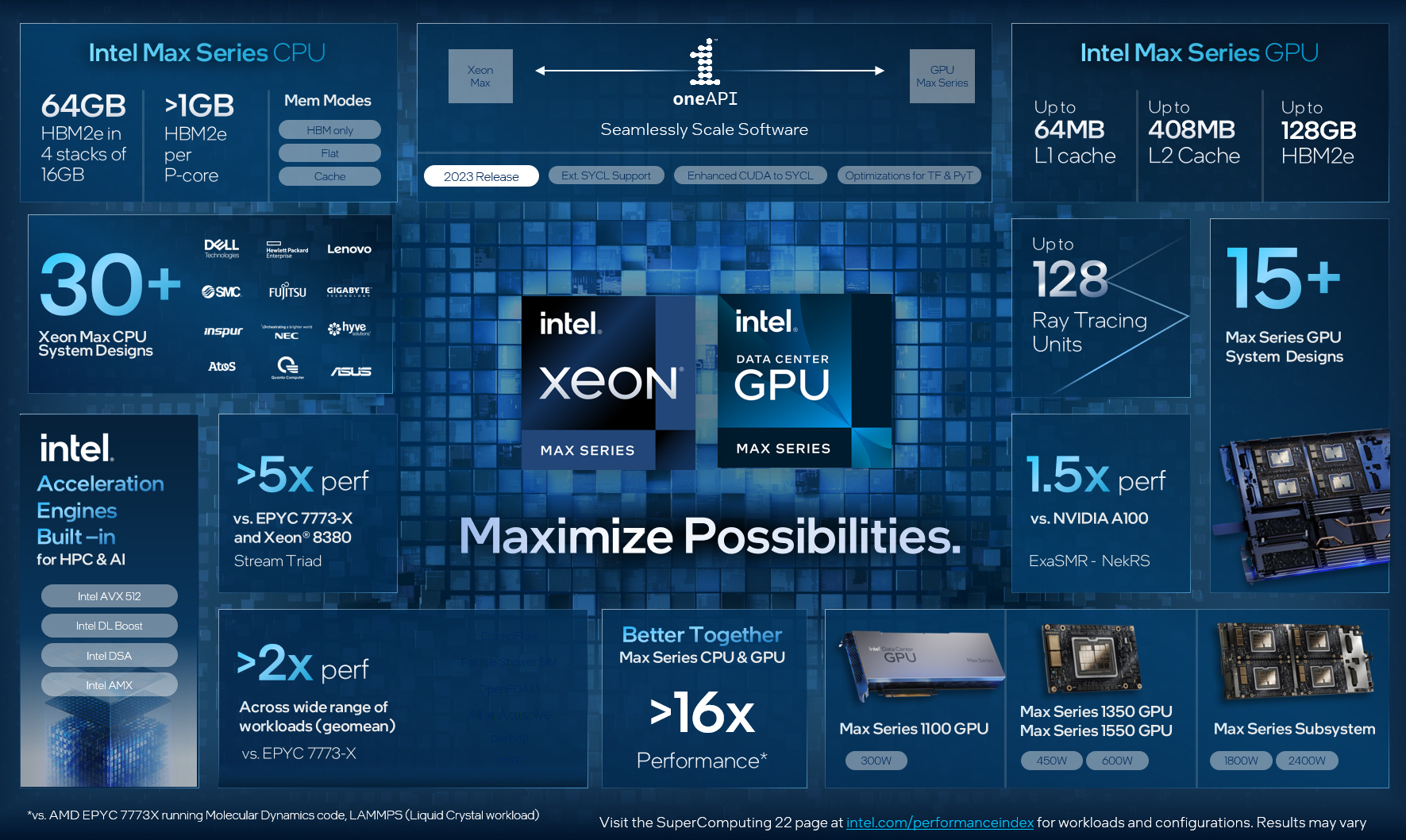
Изображения: Intel Intel Xeon Max предложат до 56 P-ядер, 112,5 Мбайт L3-кеша, 64 Гбайт HBM2e-памяти (четыре стека) с пропускной способностью порядка 1 Тбайт/с, 8 каналов памяти (DDR5-4800 в случае 1DPC, суммарно до 6 Тбайт), а также интерфейсы PCIe 5.0, CXL 1.1, UPI 2.0 и целый ряд различных технологий ускорения для задач HPC и ИИ: AVX-512, DL Boost, AMX, DSA, QAT и т.д. Заявленный уровень TDP составляет 350 Вт.  Первым процессором с набортной HBM-памятью был Arm-чип Fujitsu A64FX (48 ядер, 32 Гбайт HBM2), лёгший в основу суперкомпьютера Fugaku. Intel поднимает планку, давая более 1 Гбайт быстрой памяти на каждое ядро. А поскольку процессор состоит из четырёх отдельных чиплетов, возможно создание четырёх NUMA-доменов с выделенными HBM- и DDR-контроллерами. Но и монолитный режим тоже имеется. А поддержка CXL даёт возможность задействовать RAM-экспандеры. 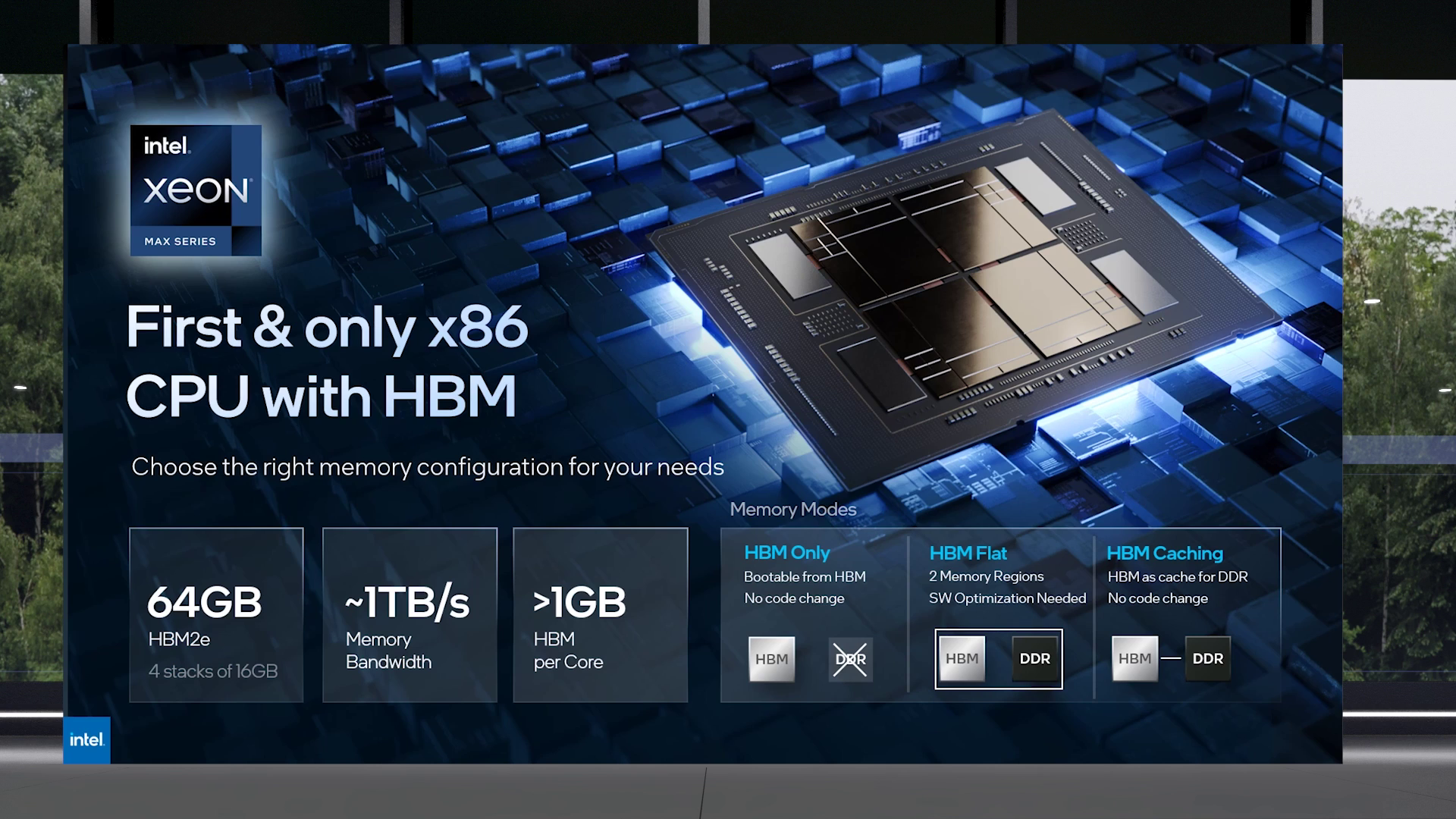 Intel Xeon Max поддерживают 2S-платформы, что суммарно даёт уже 128 Гбайт HBM-памяти, которых вполне хватит для целого ряда задач. Новые процессоры действительно могут обходиться без DIMM. Но есть и два других режима. В первом HBM-память работает в качестве кеша для обычной памяти, и для системы это происходит прозрачно, так что никаких модификаций для ПО (как в случае отсутствия DIMM вообще) не требуется. Во втором режиме HBM и DDR представлены как отдельные пространства, так что тут дорабатывать ПО придётся, зато можно добиться более эффективного использования обоих типов памяти.
В презентации Intel сравнивает новые Xeon Max с AMD EPYC Milan-X – в зависимости от задачи прирост составляет от +20 % до 4,8 раз. Но, во-первых, уже сегодня эти тесты потеряют всякий смысл в связи с презентацией EPYC Genoa (которые, к слову, должны получить AVX-512), а во-вторых, в следующем году AMD обещает представить Genoa-X с 3D V-Cache. Intel же явно не оставляет попытки создать как можно более универсальный процессор.  Что касается Ponte Vecchio, которые теперь называются Max GPU, то практически ничего нового относительно строения и особенностей данных ускорителей Intel не сказала: до 128 ядер Xe (только теперь стало известно об аппаратном ускорении трассировки лучей, что важно для визуализации), 64 Мбайт L1-кеша и аж 408 Мбайт L2-кеша (из них 120 Мбайт приходится на Rambo-кеш в двух стеках), 16 линий Xe Link, 8 HBM2e-контроллеров на 128 Гбайт памяти и пиковая FP64-производительность на уровне 52 Тфлопс. Все эти характеристики относятся к старшей модели Max Series 1550 в OAM-исполнении с TDP в 600 Вт.  Max Series 1350 предложит 112 ядер Xe и 96 Гбайт HBM2e, но и TDP у этой модели составит всего 450 Вт. Для обеих OAM-версий также будут доступны готовые блоки из четырёх ускорителей (по примеру NVIDIA RedStone), объединённых по схеме «каждый с каждым», так что в сумме можно получить 512 Гбайт HBM2e с ПСП в 12,8 Тбайт/с. Ну а самый простой ускоритель в серии называется Max Series 1100. Это 300-Вт PCIe-плата с 56 Xe-ядрами, 48 Гбайт HBM2e и мостиками Xe Link.  Intel утверждает, что ускорители Max до двух раз быстрее NVIDIA A100 в некоторых задачах, но и здесь история повторяется — нет сравнения с более современными H100. Хотя предварительный доступ к этим ускорителям у Intel есть, поскольку именно Sapphire Rapids являются составной частью платформы DGX H100. В целом, Intel прямо говорит, что наибольшей эффективности вычислений позволяет добиться связка CPU и GPU серии Max в сочетании с oneAPI. Всего на базе решений данной серии готовится более 40 продуктов.
Пока что приоритетным для Intel проектом является 2-Эфлопс суперкомпьютер Aurora, для которого пока что создан тестовый кластер Sunspot со 128 узлами, содержащими ускорители Max. Следующим ускорителем Intel станет Rialto Bridge, который появится в 2024 году. Также компания готовит гибридные (XPU) чипы Falcon Shores, сочетающие CPU, ускорители и быструю память. Аналогичный подход применяют AMD и NVIDIA.
04.10.2022 [13:30], Алексей Степин
Intel позволит применять видеокарты Arc A770 в серверах, но с ограничениямиНа мероприятии Innovation 2022 компания Intel продемонстрировала графический ускоритель Arc A770, предназначенный для рынка настольных платформ — игровых ПК и рабочих станций. Кроме того, новинку получится использовать и в серверах, но с рядом ограничений. Напомним, что A770 — это видеокарта среднего уровня на базе графического процессора ACM-G10 с 32 ядрами Xe (4096 блоков FP32, 32 блока трассировки лучей и 512 блоков матричных вычислений XMX). GPU способен работать на частоте 2,1 ГГц, он будет дополнен 8 или 16 Гбайт памяти GDDR6, в последнем случае используется 256-битная шина с ПСП около 560 Гбайт/с. Стоимость эталонной Intel Arc A770 Limited Edition составит $329. 
Источник изображений: Serve The Home Эталонный дизайн компактен по нынешним меркам: карта занимает всего два слота в высоту и охлаждается парой сравнительно небольших вентиляторов. Питание организовано по схеме 6+8 pin. Одна маленькая деталь свидетельствует о том, что Arc A770 будет устанавливаться не только в игровые ПК, но и в рабочие станции — это отверстия для крепления фиксатора в задней части карты. Пластина фиксатора входит в специальную стойку с прорезями в передней части корпуса и не даёт длинным платам провисать и перегружать механически слот PCI Express. В игровых ПК это решение не применяется, но часто встречается в серверах и рабочих станциях. 
Хорошо видны отверстия для крепления поддерживающего плату фиксатора Intel отметила, что не планирует ограничить сферу применения Arc A770 игровыми ПК или рабочими станциями. Ускорители можно будет использовать и в серверах, однако здесь обнаружился нюанс: в выступлении было отмечено, что новые ускорители не получат полноценной поддержки SR-IOV. Напомним, что SR-IOV — неотъемлемая часть любого адаптера, который должен будет работать в средах с виртуализацией, поскольку именно эта технология обеспечивает быстрый доступ виртуальных машин к аппаратным ресурсам устройства. Таким образом, применение ускорителей Intel Arc в серверах, похоже, будет ограниченным.
24.08.2022 [21:16], Алексей Степин
Intel переименовала свои первые серверные ускорители Intel Arctic Sound-M во FlexРанее мы уже рассказывали об ускорителях Intel Arctic Sound-M, о которых впервые стало известно ещё зимой. Это универсальное решение, базирующееся на графической архитектуре Xe-HPG и предназначенное для решения широкого круга задач, от организации виртуальных рабочих мест до применения в системах машинной аналитики. Сегодня Intel официально заявила, что ускорители Arctic Sound-M теперь будут доступны под брендом Flex. В основе по-прежнему лежит микроархитектура DG2 Alchemist, и компания позиционирует Flex как решение, способное ощутимо снизить стоимость владения для серверной инфраструктуры, особенно занятой в задачах транскодирования видеопотоков. 
Источник: Intel Intel заявляет, что Flex 140 в пять раз превосходит NVIDIA A10 в задачах транскодирования видео, вдвое — в сценариях декодирования, и всё это с вдвое меньшим уровнем энергопотребления, а значит, и тепловыделения. Речь идёт о младшем решении в серии с интерфейсом PCIe 4.0 x8, которое имеет два восьмиядерных чипа Xe (1600/1950 МГц) и 12 Гбайт GDDR6-памяти (192 бит, 336 Гбайт/с). Flex 170 оснащён одним чипом, но в 32-ядерном варианте (1950/2050 МГц), и имеет вдвое более высокий теплопакет (150 против 75 Вт), а также 16 Гбайт GDDR6 (256 бит, 576 Гбайт/с) и интерфейс PCIe 4.0 x16. 
Источник: Intel До 10 ускорителей Flex 140 можно разместить в стандартном 4U-шасси, что позволит одновременно обрабатывать до 360 потоков 1080р60 HEVC. Производительность Flex 140 достаточно высока, чтобы гарантировать задержку не более 1 сек при начале транскодирования видеопотока с параметрами 8K@60 (AV1 или HEVC HDR). Intel активно делает упор на аппаратной поддержке видеостандарта AV1, но ускорители работают и с HEVC, AVC и VP9. 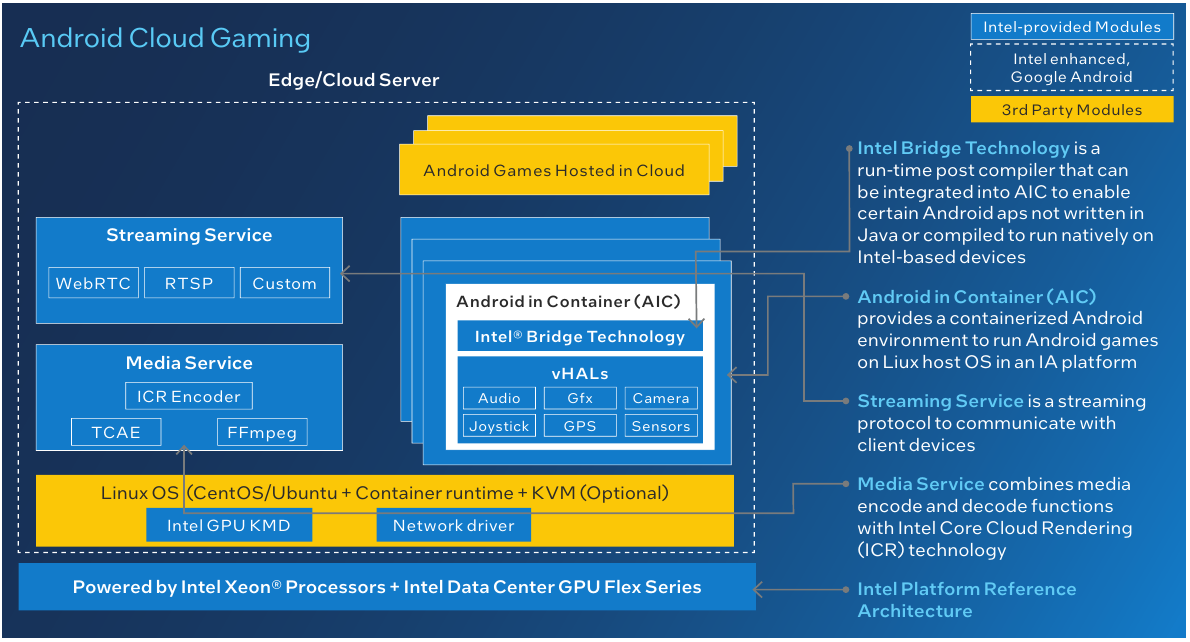
Архитектура облачного Android-гейминга Intel. Источник: Intel Также найдут своё применения ускорители Intel Flex Series и в облачных игровых платформах для Android, где единственная плата Flex 170 сможет обслуживать до 68 сессий в режиме 720p30, а шесть ускорителей Flex 140 будут в состоянии обеспечить до 216 игровых сессий с такими же параметрами. Помимо всего прочего поддерживается и аппаратное ускорение трассировки лучей. Работают новые ускорители под управлением унифицированной платформы oneAPI. 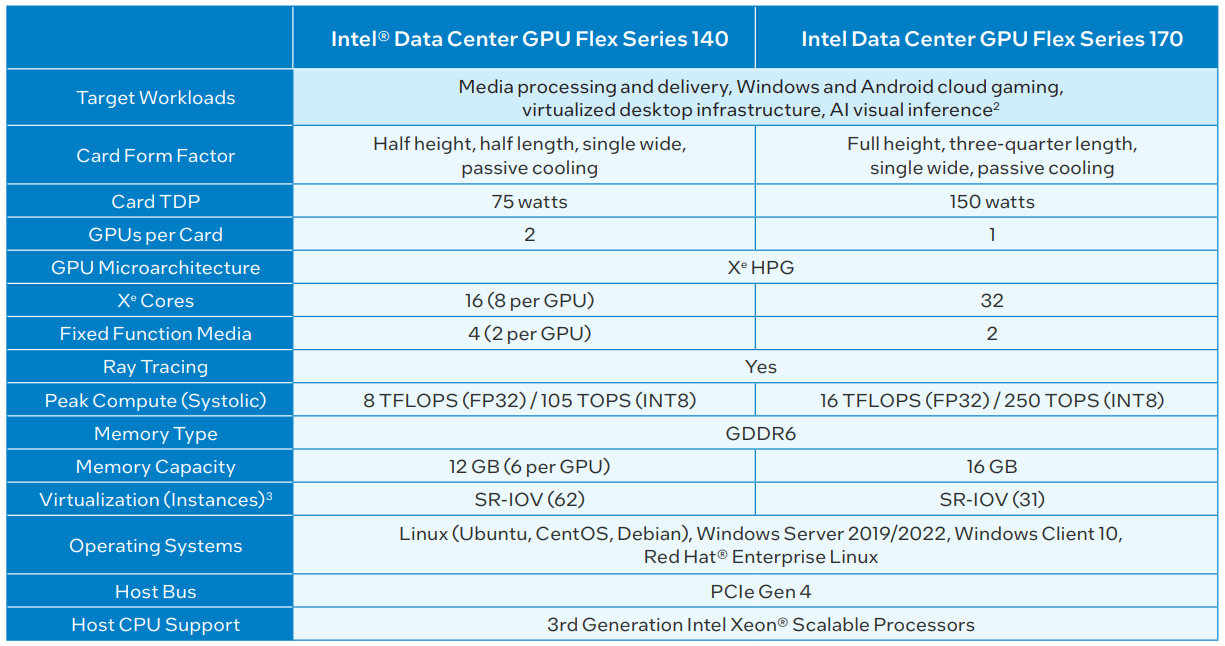 Стоимости новых ускорителей Intel пока не разглашает, но с учётом того, что компания сильно упирает на снижение стоимости владения, цена, судя по всему, будет сравнительно доступной и наверняка более привлекательной, чем у NVIDIA A10. Кроме того, Intel говорит об отсутствии необходимости докупать лицензии, чтобы воспользоваться всеми возможностями ускорителей. Но умалчивает, что производительность старшей модели Flex 170 в INT8-вычислениях совпадает с таковой у A10 (250 Топс), а в FP32-расчётах решение Intel и вовсе проигрывает. К тому же у A10 в полтора раза больше RAM.
23.08.2022 [01:17], Игорь Осколков
Производительность Intel Ponte Vecchio до 2,5 раз выше, чем у NVIDIA A100На конференции HotChips 34 компания Intel поделилась некоторыми подробностями о своих топовых ускорителях Ponte Vecchio, уточнив, в частности, производительность и некоторые характеристики новых чипов. Как и было сказано год назад, Ponte Vecchio включают два стека, которые в сумме дают 128 Xe-ядер, 128 RT-блоков, 8 контроллеров памяти HBM2e, два блока L2-кеша, два медиа-движка и 16 интерфейсов Xe Link. Всё это упаковано в OAM-модуль с TDP на уровне 600 Вт. Ускоритель состоит из 47 различных тайлов (чиплетов), изготовленных с использованием техпроцессов Intel 7/TSMC N7/TSMC N5 и объединённых между собой посредством Foveros и EMIB. Общий транзисторный бюджет — более 100 млрд. Базовая (Base) «подложка», которая несёт на себе часть тайлов, будет иметь площадь 650 мм2, максимальная площадь тайла наверху этого слоёного пирога не превысит 41 мм2, а общая площадь упаковки составит 4843,75 мм2 (77,5 × 62,5 мм). Intel будет предлагать как отдельные OAM-модули, так и сборки из четырёх ускорителей. 
Изображения: Intel (via WCCFtech)  Ускоритель отличается развитой иерархией памяти. На самом нижем уровне лежат регистровые файлы суммарным объёмом 64 Мбайт, обеспечивающие пропускную способность (ПСП) до 419 Тбайт/с. L1-кеш имеет тот же объём, но скорость поменьше — 105 Тбайт/с. L2-кеш намеренно увеличен до 408 Мбайт, а его ПСП составляет 13 Тбайт/с. Наконец, на вершине находятся 128 Гбайт HBM2e с ПСП на уровне 3,2 Тбайт/с. Но надо учитывать, что данные даны для двух стеков, связанных мостиками. Xe Link же позволяет объединить четыре или восемь ускорителей по схеме каждый-с-каждым. 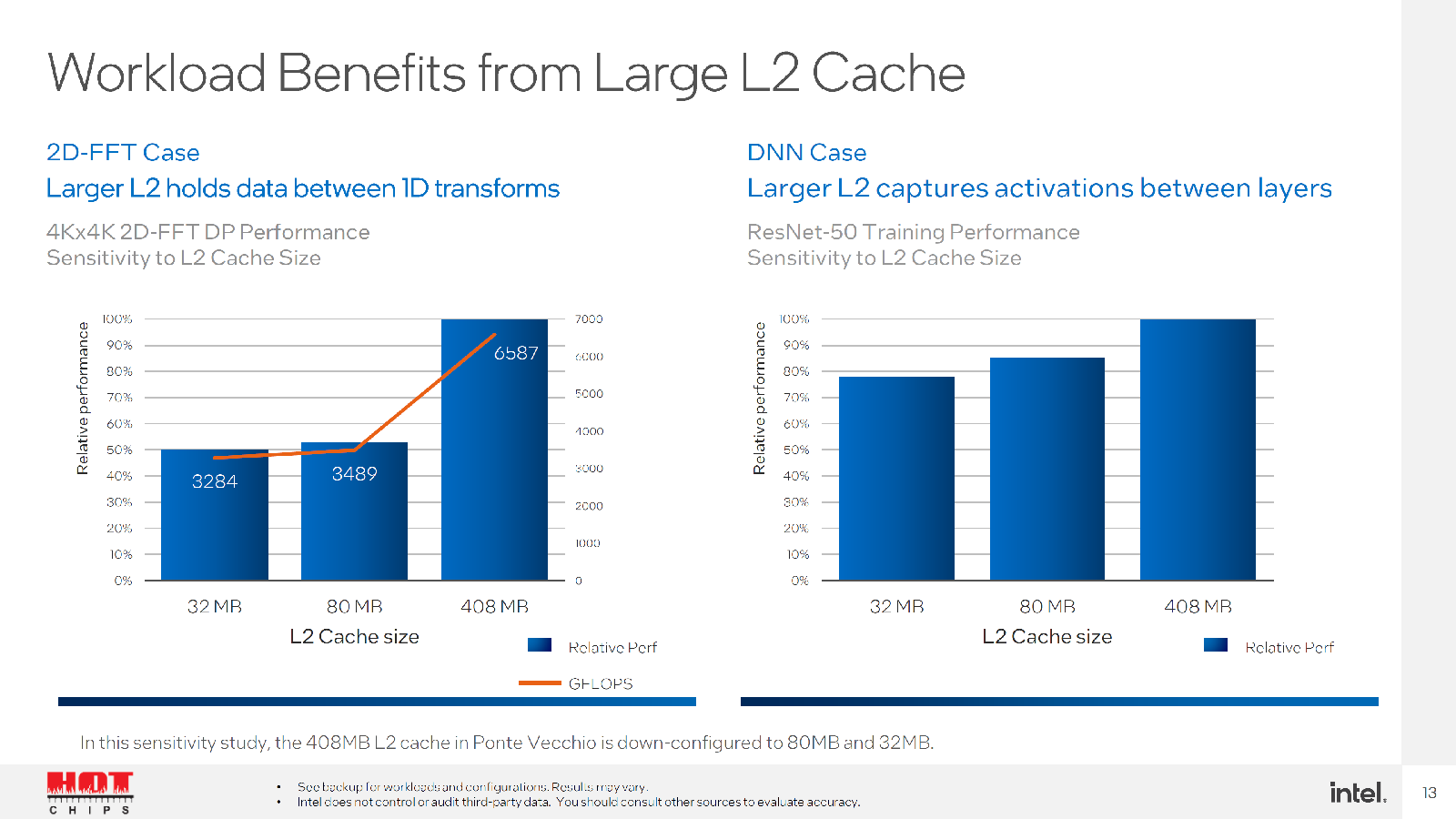 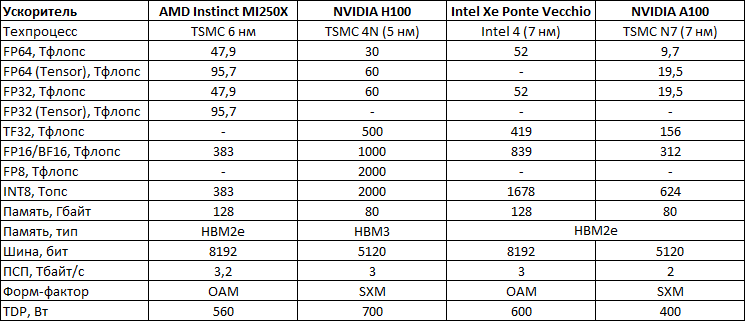 Увеличенный объём L2-кеша, по словам Intel, оказывает значительное влияние на производительность в некоторых задачах. Заявленная производительность составляет 52 Тфлопс для FP64/FP32-вычислений, 419 Тфлопс для TF32, 839 Тфлопс для BF16/FP16 и, наконец, 1678 Топс для INT8. Все вычисления пониженной точности даны для матричных блоков XMX. По «голым» характеристикам Ponte Vecchio действительно намного быстрее NVIDIA A100, а по некоторым пунктам — и AMD Instinct MI250X. Оптимизированное ПО, использующее oneAPI, до двух раз быстрее исполняется на ускорителях Intel по сравнению с A100, но результат, конечно, зависит от задачи. 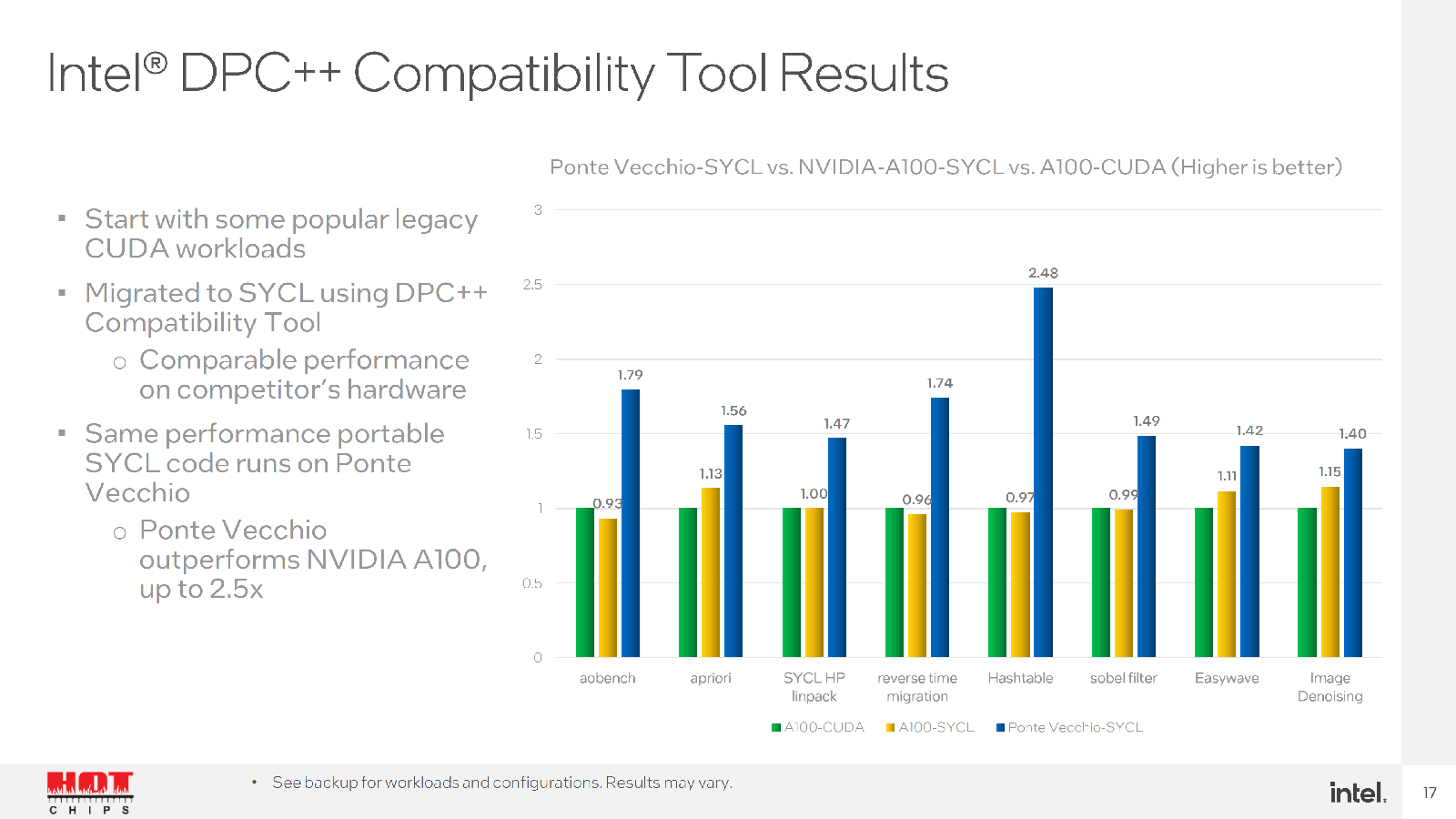
Но у Intel есть ещё один козырь. Во-первых, компания обещает, что часть старых кодов, оптимизированных ещё для CPU можно быстро перенести на её ускорители. Во-вторых, она предлагает инструмент для быстрого перевода CUDA-программ на SYCL. Любопытно, что после такого переноса часть ПО работает на ускорителях NVIDIA лучше прежнего, а на ускорителях Intel — до 2,5 раз. Правда, A100 уже более двух лет. И буквально за углом нас ждёт ускоритель H100, который даже на бумаге практически по всем пунктам опережает Ponte Vecchio.
27.07.2022 [13:27], Алексей Степин
Начались поставки серверных ускорителей Intel Arctic Sound-MАрхитектура Intel Xe интересна не только тем, что с ней компания пытается войти на рынок, где десятилетиями идёт война между «красными» и «зелёными». Они также служат основой для серверных ускорителей Arctic Sound-M (ATS-M), которые оптимизированы для обеспечения низкой совокупной стоимости владения (TCO). Анонсированы эти ускорители были ещё зимой этого года именно как решение для ускорения обработки видео, организации виртуальных рабочих мест, облачного гейминга и систем машинной аналитики, в чём им должна была помогать открытость платформы. Наконец, вчера Intel официально сообщила о начале поставок плат Arctic Sound-M. 
Источник: Intel В мае компания анонсировала две модификации ATS-M: полноразмерный вариант с 32 ядрами Xe (150 Вт) и компактный низкопрофильный, несущий на борту 16 ядер Xe (75 Вт). Теплопакеты достаточно скромные, поэтому разработчикам удалось сделать решение на его основе однослотовым и обойтись пассивным охлаждением. Обе модификации имеют интерфейс PCIe 4.0 x16 и снабжаются GDDR6-памятью. Ускорители отличаются наличием высокоэффективного аппаратного (де-)кодера AV1 и блоков ускорения трассировки лучей, что как раз и делает их идеальными для облачного гейминга. Впрочем, как уже было сказано, это не единственная сфера применения Arctic Sound-M: один такой ускоритель может обслуживать десятки VDI-сессий с полноценным десктопным окружением, а также развивает неплохие 150 Топс в инференс-задачах (INT8).
26.06.2022 [15:47], Алексей Степин
Основой суперкомпьютера MareNostrum-5 всё же станут процессоры Intel Xeon Sapphire Rapids и ускорители NVIDIA H100
atos
grace
h100
hardware
hpc
ibm
intel
intel xe
lenovo
nvidia
sapphire rapids
xeon
европа
испания
суперкомпьютер
Евросоюз явно отстаёт в гонке экзафлопсных суперкомпьютеров, а у одного из крупнейших проектов, MareNostrum-5, сложная судьба — строительство системы постоянно откладывалось. Не столь давно, наконец-то, процесс возобновился, главным поставщиком стала Atos с её новой платформой BullSequana XH3000, причём в составе машины будут использоваться новые Arm-чипы NVIDIA Grace. Но, как выяснил ресурс The Next Platform, основой суперкомпьютера будут вовсе не они. Да и подрядчик в проекте тоже не один. 
Изображение: BSC Пиковая FP64-производительность составит 314 Пфлопс в HPL, а устоявшаяся — 205 Пфлопс. Однако почти ⅘ из них (163 Пфлопс) обеспечат узлы XH3000 с двумя процессорами Intel Xeon Sapphire Rapids и четырьмя ускорителями NVIDIA H100. В пике они дадут до 270 Пфлопс в FP64, а в вычислениях с пониженной точностью — как раз обещанные 18 Эфлопс. Ещё один кластер будет состоять из узлов Lenovo ThinkSystem SD650 V3, содержащих только CPU Sapphire Rapids, которые суммарно дадут ещё 36 Пфлопс. 
Изображение: BSC Третий кластер получит следующие поколения процессоров Intel Xeon — Emerald Rapids — и ускорителей Xe Rialto Bridge. Но этот раздел совсем невелик — на него придётся всего 2% мощностей MareNostrum-5, т.е. около 4 Пфлопс. Наконец, самую меньшую долю составят спарки NVIDIA Grace, развивать они будут всего около 2 Пфлопс, менее 1% запланированной мощности системы в Linpack. Два вышеописанных кластера описываются как экспериментальные. А вот сведения о подсистемах хранения данных изначально были опубликованы верные. Систему объединит 400G-сеть InfiniBand NDR (Quantum-2), для хранения «горячих данных» будет применен кластер IBM Elastic Storage Server с файловой системой Spectrum Scale объёмом более 200 Пбайт. Архивное хранилище, тоже от IBM, будет иметь объём 400 Пбайт. Остаётся надеяться, что более задержек не будет, а имеющиеся проблемы с началом массового производства чипов Sapphire Rapids будут успешно решены.
31.05.2022 [22:30], Игорь Осколков
На смену Intel Ponte Vecchio придут ускорители Rialto BridgeНа конференции ISC 2022 компания Intel сделала несколько анонсов, касающихся дальнейшего развития продуктов для высокопроизводительных вычислений (HPC). В частности, компания впервые рассказала о наследнике Ponte Vecchio — ускорителе под кодовым названием Rialto Brdige, первые образцы которого должны появиться в середине 2023 года. Rialto Bridge предложит эволюционное развитие идей, заложенных в Ponte Vecchio, поскольку получит ту же архитектуру, но с улучшениями в части памяти и вычислений. Итоговый прирост производительности должен составить около трети. Intel также упоминает возможность бесшовного переноса ПО на новые ускорители и обещает повысить производительность подсистемы ввода-вывода, не уточняя деталей. Это может касаться основной памяти, интерконнекта Xe Link и PCIe/UCIe. Единственная однозначная спецификация — переход к форм фактору OAM 2.0, который допускает энергопотребление на уровне 800 Вт. 
Изображения: Intel Rialto Bridge получат до 160 ядер Xe, тогда как у них предшественников их 128. Тайлы (или чиплеты) «переедут» на более тонкие техпроцессы в рамках стратегии IDM 2.0, но Intel пока не говорит, где какие блоки будут производиться. Также можно заметить некоторые изменения в компоновке чипа. Общее число Xe-тайлов (8 шт.) не увеличилось, то есть теперь в каждом из них 20 ядер Xe, а не 16. Ну и отдельного блока Rambo Cache теперь тоже нет, но это не значит, что от него избавились. Вероятнее всего, он перебрался поближе к вычислительным блокам.  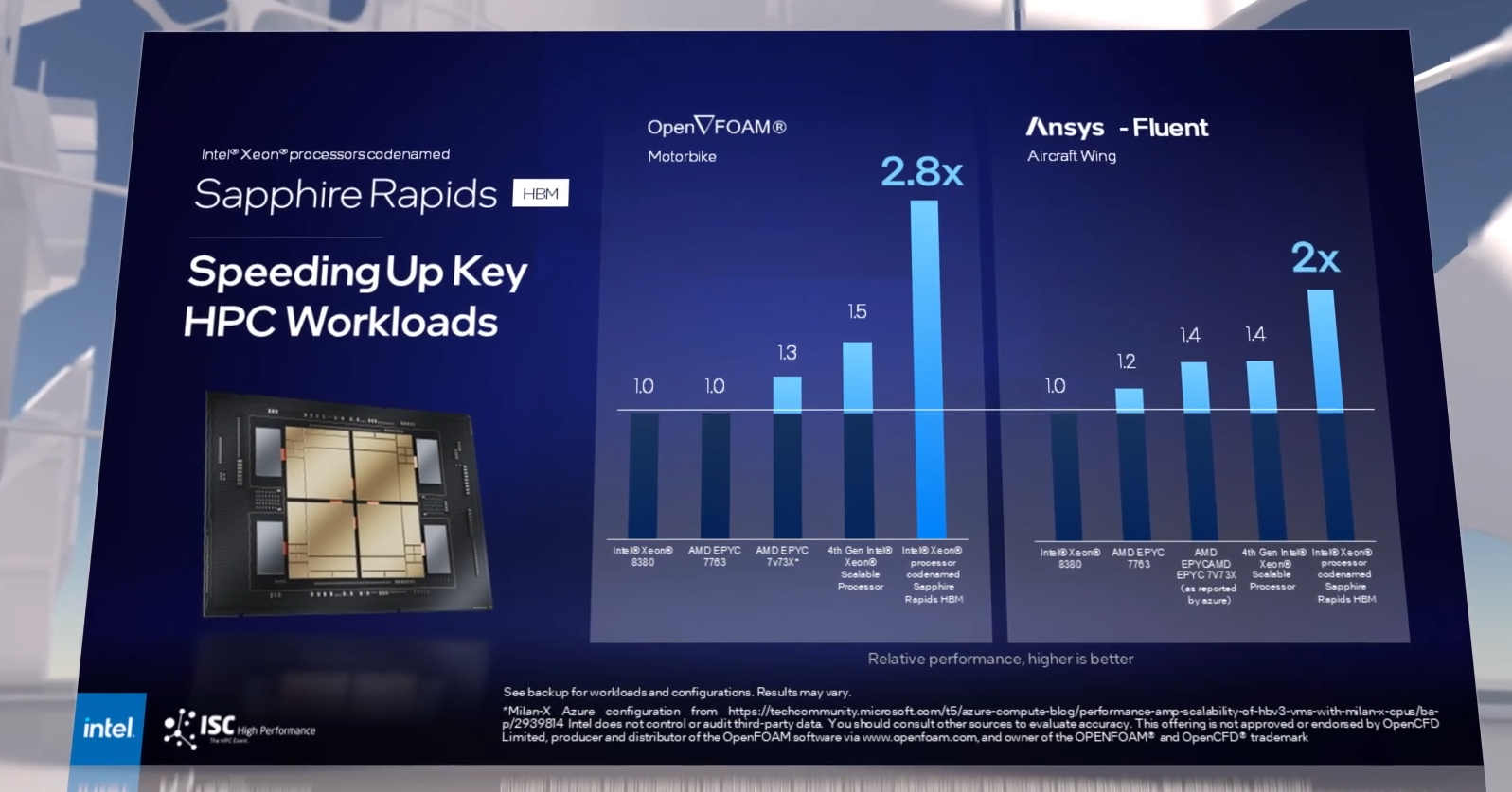 Также на ISC 2022 компания напомнила о гибридных ускорителях Falcon Shores с настраиваемым соотношением CPU- и Xe-ядер, анонсированных зимой, и показала результаты некоторых тестов грядущих Intel Xeon Sapphire Rapids с набортной HBM-памятью (до двух-трёх раз быстрее Ice Lake-SP) и Ponte Vecchio. Естественно, в оптимизированных бенчмарках, о чём неоднократно и сообщала, напоминая, что без должной экосистемы ПО любое «железо» смысла не имеет. И в развитие этой системы, в том числе open source, компания активно вкладывается — к текущему моменту она открыла два десятка совместных центров развития oneAPI. Впрочем, на системном ПО Intel также планирует зарабатывать.   Последний на сегодня анонс касается нового открытого продукта XPU Manager, который, судя по всему, является развитием DCM-инструментов Intel. Несмотря на многообещающее название, он пока предназначен только для серверных ускорителей Intel и других производителей. XPU Manager позволяет централизованно, локально или удалённо проактивно следить за их состоянием, проводить глубокую диагностику, настраивать энергопотребление и температурные режимы, а также управлять политиками доступа. Все эти программно-аппаратные новинки подаются под соусом заботы об экологии, поскольку повышение эффективности их работы должно помочь Intel достичь нулевого выброса парниковых газов к 2040 году. |
|


